框架设计
thread cache是哈希桶的结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表,我们知道定长内存池只有一个自由链表,因为它每个内存块对象大小相等,但是我们这个内存池需要支持不同大小的内存块,所以需要多个自由链表。
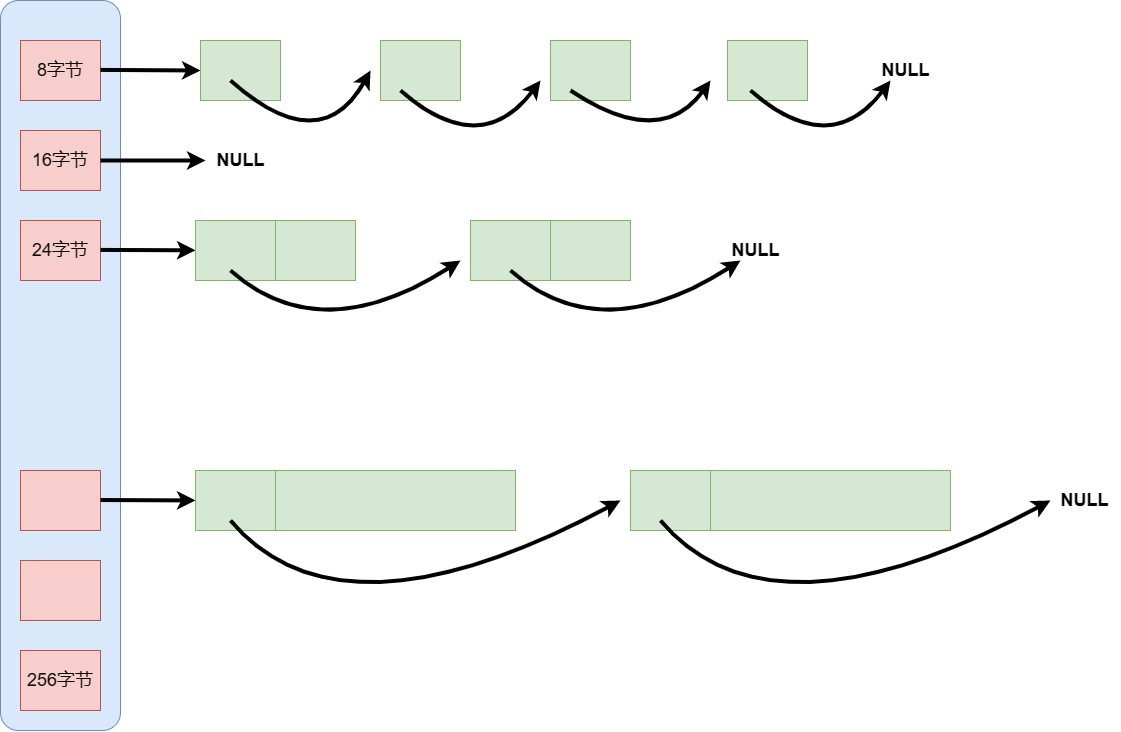
具体抽象结构大致如上,每个线程都会有一个thread cache对象,这样每个线程在这里获取对象和释放对象的时候是无锁的。
申请内存
- 当内存申请size<=256kb时,先获取线程本地存储的thread cache对象,计算size映射的哈希桶自由链表的下标i
- 如果自由链表的freeLists[i] 中有对象,则直接Pop一个内存对象返回
- 如果freeLists[i]中没有对象,则批量从central cache中获取一定数量的对象,插入到自由链表,并返回一个对象
释放内存
- 当释放内存小于256kb时将内存释放回thread cache,计算size映射自由链表桶位置i,将对象Push到freeList[i]
- 当链表的长度过长,则回收一部分内存对象到central cache
内存碎片
外碎片问题前边已经讲过,这里只说一下内碎片的问题,如果我们将每种字节数都用一个自由链表管理,那么256kb就是256* 1024个自由链表,这样自由链表的数量会太多,这些头指针就会占据大量内存。所以可以采取类似上边抽象图。8字节对齐,16字节…
我们所用对象的大小可能并不是准确的8、16…,有可能是1字节,14字节,但是我们仍然给对应的8字节16字节,那么就会有部分内存浪费,也就是内碎片问题
具体实现
对齐规则
我们thread cache,底层是哈希桶,我们希望桶的数量不那么多,同时内碎片的浪费综合起来也不那么多。综合考量,使不同范围内的字节数按照不同的对齐数对齐,如下所示:
| 字节数 |
对齐数 |
哈希桶下标 |
| 1 ~ 128 |
8字节对齐 |
0 - 15 |
| 128+1 ~ 1024 |
16字节对齐 |
16 - 71 |
| 1024+1 ~ 8*1024 |
128字节对齐 |
72 - 127 |
| 8*1024+1 ~ 64*1024 |
1024字节对齐 |
128 - 183 |
| 64*1024+1 ~ 256*1024 |
8*1024字节对齐 |
184 - 207 |
举几个例子:
- 1~128字节,都按8字节对齐,也就是1字节的话,会给你8字节,浪费7个字节
- 129~1024字节,按16字节对齐,申请129会给129+16-1=144字节,会浪费15字节,比重为:15/144
- 1025~8*1024字节,按128字节对齐,申请1025会给1025+128-1=1152字节,浪费127字节,比重为:127/1152
- …
1~128字节区间最多浪费7个字节,后面范围浪费字节的比重大概都在10%左右。
功能实现
ThreadCache类
我们先定义这个threadcache类,功能有申请内存、释放内存和从中心缓存获取对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class ThreadCache
{
public:
void* Allocate(size_t size);
void Deallocate(void* obj, size_t size);
void* FetchFromCentralCache(size_t index, size_t size);
private:
FreeList _freeLists[NFREELIST];
};
|
自由链表类
我们的是管理自由链表的哈希桶,自由链表有多个,定义一个类实现,功能和实现我们之前的定长内存池一样,成员就是一个void*的指针,提供push、pop和empty接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| static void*& NextObj(void* obj)
{
return *(void**)obj;
}
class FreeList
{
public:
void Push(void* obj)
{
assert(obj);
NextObj(obj) = _freeList;
_freeList = obj;
}
void* Pop()
{
assert(_freeList);
void* obj = _freeList;
_freeList = NextObj(_freeList);
return obj;
}
bool Empty()
{
return _freeList == nullptr;
}
private:
void* _freeList = nullptr;
};
|
ThreadCache类实现
然后就是 ThreadCache类中成员函数的具体实现,也就是如何申请释放内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
void* ThreadCache::Allocate(size_t size)
{
assert(size <= MAX_BYTES);
}
void ThreadCache::Deallocate(void* obj, size_t size)
{
}
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
}
|
对齐+计算下标
但是开始我们就会面临一个问题,我们申请内存,首先是要看哈希桶的自由链表,我们就要知道申请的字节数对应哪个哈希桶的自由链表,这里涉及到对齐和计算哈希桶下标,我们还是用一个类管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
class SizeClass
{
public:
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8*1024);
}
else
{
assert(false);
}
}
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
static int group_array[4] = { 16, 56, 56, 56 };
if (bytes <= 128){
return _Index(bytes, 3);
}
else if (bytes <= 1024){
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024){
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 64 * 1024){
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024){
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else{
assert(false);
}
return -1;
}
};
|
对齐
我们用一个子函数实现这个功能
常规写法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| size_t _RoundUp(size_t bytes, size_t alignNum)
{
if (bytes % alignNum == 0)
{
return bytes;
}
else
{
return (bytes / alignNum + 1) * alignNum;
}
}
|
牛比写法:
1
2
3
4
| size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
|
具体例子说明:
字节数为1,应该对齐到8
前半部分:1+8-1=8 二进制:0000 1000
后半部分:8-1=7 二进制:0000 0111
8 &~ 7 = 8
字节数为10,应该对齐到16
前半部分:10+8-1=17 二进制:0001 0001
后半部分: 8-1=7 二进制:0000 0111
10 &~7 = 10000 = 16
8:1000
~7:1111 1000
别的数和~7相与,后3位会变成0
16:10000
~15:1111 0000
别的数和~15相与,后4位会变成0
…
它的原理是让当前的字节数+对齐数-1,这样就大于或等于一个向上对齐的大小,然后与后面一部分相与,去掉多余的部分
计算下标
1字节,在0号桶
10字节,在1号桶
…
129字节,在16号桶
···
1
2
3
4
| static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
|
和上边算对齐数有点像
比如 1字节:
- 1+(1<<3) -1 = 8 (部分是当前字节数加了一个对齐数-1,这个数大于等于当前字节所要对齐的那个对齐数)
- 8>>3=1 (相当于除以一个对齐数)
- 1-1=0
比如10字节:
- 10+(1<<3)-1=17
- 17>>3=2
- 2-1=1
ThreadCache类继续
完成上边的功能后,我们可以具体写ThreadCache类的实现了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| void* ThreadCache::Allocate(size_t size)
{
assert(size <= MAX_BYTES);
size_t alignSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(size);
if (!_freeLists[index].Empty())
{
return _freeLists[index].Pop();
}
else
{
return FetchFromCentralCache(index, alignSize);
}
void ThreadCache::Deallocate(void* obj, size_t size)
{
assert(obj);
assert(size <= MAX_BYTES);
size_t index = SizeClass::Index(size);
_freeLists[index].Push(obj);
}
}
|
ThreadCache无锁访问
每个线程都有自己的thread cache,如何创建这个thread cache呢?如果创建为全局,那么肯定是需要锁来控制
如果实现每个线程无锁的访问thread cache,就需要用到线程局部存储TLS(Thread Local Storage),使用该方式存储的遍历在它所在的线程全局是可访问的,但是不能被其他线程访问到,可以保证线程的独立性。
我们在 声明下边这个指针、
1
2
|
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
|
在整个调用中可以用下述方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| static void* ConcurrentAlloc(size_t size)
{
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;
return pTLSThreadCache->Allocate(size);
}
static void ConcurrentDealloc(void* ptr, size_t size)
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr, size);
}
|

 微信
微信 支付宝
支付宝